多线程学习3 goruntine
Contents
两级线程模型
多线程学习2中讲到了内核级线程和用户级线程用组合的方式形成的混合型线程模型,也就是两级线程模型。
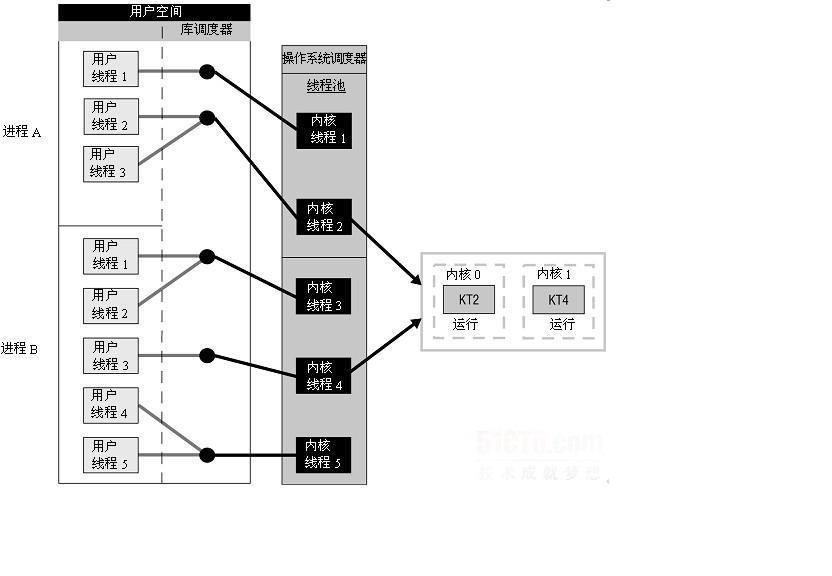
两级线程模型是博采众长之后的产物,充分吸收前两种线程模型(内核级线程模型和用户级线程模型)的优点且尽量规避它们的缺点。在此模型下,用户线程与内核KSE是多对多(N : M)的映射模型: 首先,区别于用户级线程模型,两级线程模型中的一个进程可以与多个内核线程KSE关联,于是进程内的多个线程可以绑定不同的KSE,这点和内核级线程模型相似; 其次,又区别于内核级线程模型,它的进程里的所有线程并不与KSE一一绑定,而是可以动态绑定同一个KSE, 当某个KSE因为其绑定的线程的阻塞操作被内核调度出CPU时,其关联的进程中其余用户线程可以重新与其他KSE绑定运行。
所以,两级线程模型既不是用户级线程模型那种完全靠自己调度的也不是内核级线程模型完全靠操作系统调度的,而是中间态(自身调度与系统调度协同工作),也就是 — 『薛定谔的模型』(误),因为这种模型的高度复杂性,操作系统内核开发者一般不会使用,所以更多时候是作为第三方库的形式出现,而Go语言中的runtime调度器就是采用的这种实现方案,实现了Goroutine与KSE之间的动态关联,不过Go语言的实现更加高级和优雅;该模型为何被称为两级?即用户调度器实现用户线程到KSE的『调度』,内核调度器实现KSE到CPU上的『调度』。
历史
在Go 1.0发布的时候,它的调度器其实G-M模型,也就是没有P的,调度过程全由G和M完成,这个模型暴露出一些问题:
- 单一全局互斥锁(Sched.Lock)和集中状态存储的存在导致所有goroutine相关操作,比如:创建、重新调度等都要上锁;
- goroutine传递问题:M经常在M之间传递『可运行』的goroutine,这导致调度延迟增大以及额外的性能损耗;
- 每个M做内存缓存,导致内存占用过高,数据局部性较差;
- 由于syscall调用而形成的剧烈的worker thread阻塞和解除阻塞,导致额外的性能损耗。
这些问题实在太扎眼了,导致 Go1.0 虽然号称原生支持并发,却在并发性能上一直饱受诟病,然后,Go语言委员会中一个核心开发大佬看不下了,亲自下场重新设计和实现了Go调度器(在原有的G-M模型中引入了P)并且实现了一个叫做 work-stealing 的调度算法:
- 每个P维护一个G的本地队列;
- 当一个G被创建出来,或者变为可执行状态时,就把他放到P的可执行队列中;
- 当一个G在M里执行结束后,P会从队列中把该G取出;如果此时P的队列为空,即没有其他G可以执行, M就随机选择另外一个P,从其可执行的G队列中取走一半。
该算法避免了在goroutine调度时使用全局锁。
至此,Go调度器的基本模型确立:
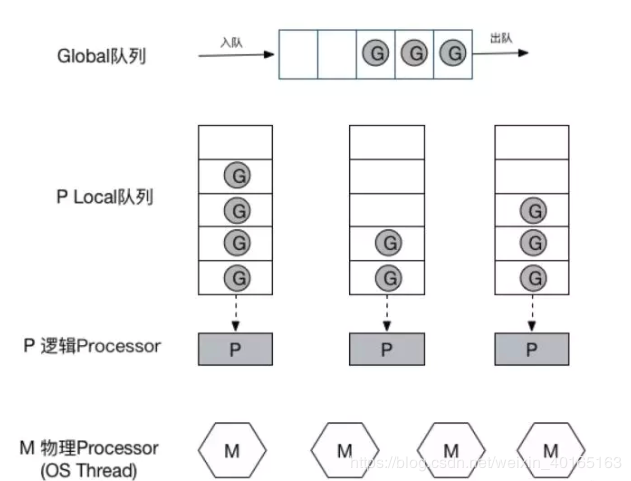
G-P-M 模型
是CSP(communicating sequential processes)并发模型的实现。
G:Goroutine的缩写,一个G代表了对一段需要被执行的Go语言代码的封装,goruntine是一种协程,协程从本质上来说是一种用户级线程,不需要系统来执行抢占式调度,而是在语言层面实现线程的调度。
M:Machine的缩写,一个M代表了一个内核线程
P:Processor的缩写,一个P代表了M所需的上下文环境
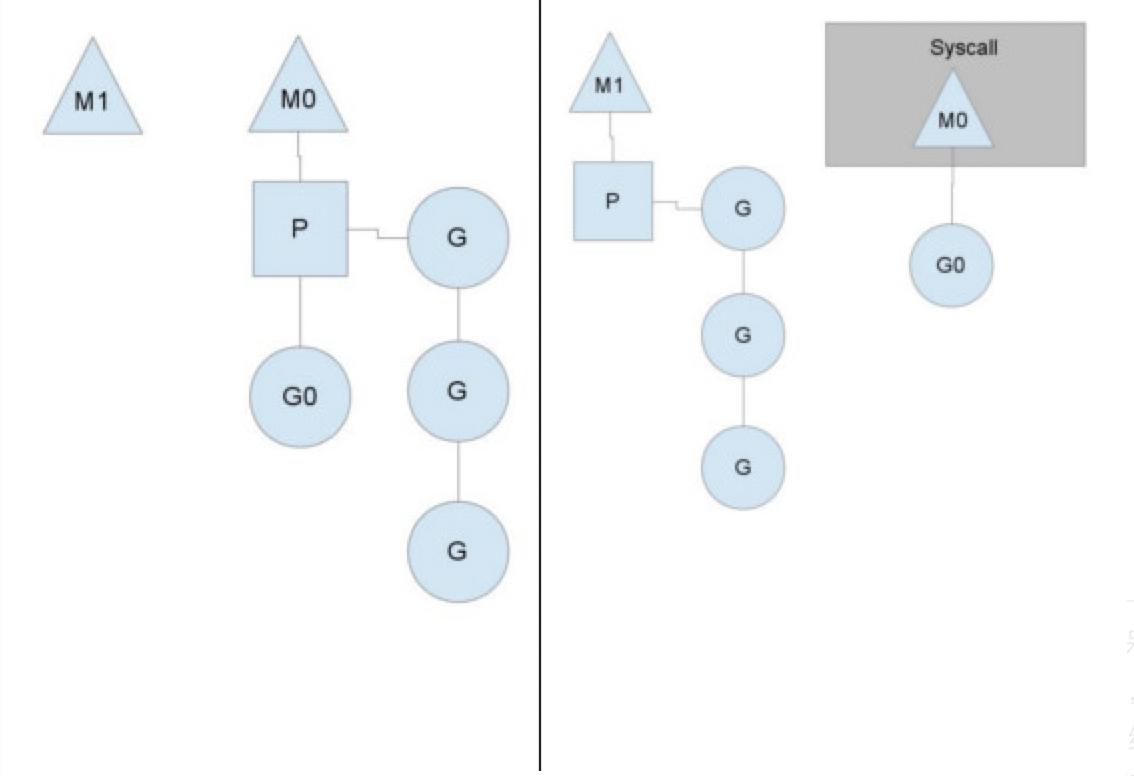 这里我们看到一个线程放弃了它的上下文,以便另一个线程可以运行它。调度程序确保有足够的线程运行所有上下文。上图中的m1可能只是为了处理这个系统调用而创建的,也可能来自线程缓存。系统调用线程将保留进行系统调用的goroutine,因为它在技术上仍在执行,尽管在操作系统中被阻塞。当系统调用返回时,线程必须尝试获取上下文才能运行返回的goroutine。正常的操作模式是从另一个线程中窃取上下文。如果它不能偷一个,它将把goroutine放在全局运行队列上,放在线程缓存上,然后进入睡眠状态。全局运行队列是上下文在用完本地运行队列时从中提取的运行队列。上下文还定期检查全局运行队列中的goroutine。否则,全局运行队列上的goroutine可能会因为饥饿而永远无法运行。这种对syscalls的处理是go程序运行多线程的原因,即使gomaxprocs是1。运行时使用调用系统调用的goroutine,从而留下线程。
这里我们看到一个线程放弃了它的上下文,以便另一个线程可以运行它。调度程序确保有足够的线程运行所有上下文。上图中的m1可能只是为了处理这个系统调用而创建的,也可能来自线程缓存。系统调用线程将保留进行系统调用的goroutine,因为它在技术上仍在执行,尽管在操作系统中被阻塞。当系统调用返回时,线程必须尝试获取上下文才能运行返回的goroutine。正常的操作模式是从另一个线程中窃取上下文。如果它不能偷一个,它将把goroutine放在全局运行队列上,放在线程缓存上,然后进入睡眠状态。全局运行队列是上下文在用完本地运行队列时从中提取的运行队列。上下文还定期检查全局运行队列中的goroutine。否则,全局运行队列上的goroutine可能会因为饥饿而永远无法运行。这种对syscalls的处理是go程序运行多线程的原因,即使gomaxprocs是1。运行时使用调用系统调用的goroutine,从而留下线程。
P(process):
P是process的头文字, 表示调度的上下文(a context for scheduling),代表M运行G所需要的资源。您可以将其视为在单个线程上运行go代码的调度程序的本地化版本。这是让我们从n:1调度程序转到m:n调度程序的重要部分。 一些讲解协程的文章把P理解为cpu核心, 其实这是错误的. 虽然P的数量默认等于cpu核心数, 但可以通过环境变量GOMAXPROC修改, 在实际运行时P跟cpu核心并无任何关联。
P也可以理解为控制go代码的并行度的机制, 如果P的数量等于1, 代表当前最多只能有一个内核级线程(M)执行go代码(原生运行时代码除外), 如果P的数量等于2, 代表当前最多只能有两个内核级线程(M)执行go代码. 而执行原生代码(如gc,sysmon等)的线程数量不受P控制,所以即使GOMAXPROCS设为1也可能会有数量大于1的M产生。
因为同一时间只有一个线程(M)可以拥有P, P中的数据都是锁自由(lock free)的, 读写这些数据的效率会非常的高。
P是使G能够在M中运行的关键。Go运行时系统适当地让P与不同的M建立或者断开联系,以使得P中的那些可运行的G能够在需要的时候及时获得运行时机。
GOMAXPROCS
runtime.GOMAXPROCS函数设置的只会影响P的数量,但是对M (内核线程)的数量不会影响,所以runtime.GOMAXPROCS 并不是控制线程数,只能说是影响上下文环境P的数目。 GOMAXPROCS的值对Go程序的可以用的P最大的数量做出预先设定,P的最大数量相当于是对可以被并发运行的用户级别的G的数量做出限制。 UPDATE 2018: By default, Go programs run with GOMAXPROCS set to the number of cores available; in prior releases it defaulted to 1.
Starting from Go 1.5, the default value is the number of cores. You only need to explicitly set it if you are not okay with this in newer Go versions.
1.5以后默认为机器可用的内核数,可以用runtime.GOMAXPROCS(0)查看。
M(machine):
M是machine的头文字, 在当前版本的golang中等同于系统线程. M可以运行两种代码:
- go代码, 即goroutine, M运行go代码需要一个P
- 原生代码, 例如阻塞的syscall, M运行原生代码不需要P
M会从运行队列中取出G, 然后运行G, 如果G运行完毕或者进入休眠状态, 则从运行队列中取出下一个G运行, 周而复始。 有时候G需要调用一些无法避免阻塞的原生代码, 这时M会释放持有的P并进入阻塞状态, 其他M会取得这个P并继续运行队列中的G. go需要保证有足够的M可以运行G, 不让CPU闲着, 也需要保证M的数量不能过多。通常创建一个M的原因是由于没有足够的M来关联P并运行其中可运行的G。而且运行时系统执行系统监控的时候(sysmon),或者GC的时候也会创建M。
M并没有像G和P一样的状态标记, 但可以认为一个M有以下的状态:
- 自旋中(spinning): M正在从运行队列获取G, 这时候M会拥有一个P
- 执行go代码中: M正在执行go代码, 这时候M会拥有一个P
- 执行原生代码中: M正在执行原生代码或者阻塞的syscall, 这时M并不拥有P
- 休眠中: M发现无待运行的G时会进入休眠, 并添加到空闲M链表中, 这时M并不拥有P
自旋中(spinning)这个状态非常重要, 是否需要唤醒或者创建新的M取决于当前自旋中的M的数量。
M在被创建之初会被加入到全局的M列表 【runtime.allm】 。接着,M的起始函数(mstartfn)和准备关联的P(p)都会被设置。最后,运行时系统会为M专门创建一个新的内核线程并与之关联。这时候这个新的M就为执行G做好了准备。其中起始函数(mstartfn)仅当运行时系统要用此M执行系统监控或者垃圾回收等任务的时候才会被设置。全局M列表的作用是运行时系统在需要的时候会通过它获取到所有的M的信息,同时防止M被gc。
在新的M被创建后会做一番初始化工作。其中包括了对自身所持的栈空间以及信号做处理的初始化。在上述初始化完成后 mstartfn 函数就会被执行 (如果存在的话)。【注意】:如果mstartfn 代表的是系统监控任务的话,那么该M会一直在执行mstartfn 而不会有后续的流程。否则 mstartfn 执行完后,当前M将会与那个准备与之关联的P完成关联。至此,一个并发执行环境才真正完成。之后就是M开始寻找可运行的G并运行之。
运行时系统管辖的M会在GC任务执行的时候被停止,这时候系统会对M的属性做某些必要的重置并把M放置入调度器的空闲M列表。【很重要】因为在需要一个未被使用的M时,运行时系统会先去这个空闲列表获取M。(只有都没有的时候才会创建M)
M本身是无状态的。M是否有空闲仅以它是否存在于调度器的空闲M列表 【runtime.sched.midle】 中为依据 (空闲列表不是那个全局列表哦)。
单个Go程序所使用的M的最大数量是可以被设置的。在我们使用命令运行Go程序时候,有一个引导程序先会被启动的。在这个引导程序中会为Go程序的运行建立必要的环境。引导程序对M的数量进行初始化设置,默认是 最大值 1W 【即是说,一个Go程序最多可以使用1W个M,即:理想状态下,可以同时有1W个内核线程被同时运行】。使用 runtime/debug.SetMaxThreads() 函数设置。
G (goroutine):
G是goroutine的头文字, goroutine可以解释为受管理的轻量线程, goroutine使用go关键词创建。
举例来说, func main() { go other() }, 这段代码创建了两个goroutine。 一个是main, 另一个是other, 【注意】:main本身也是一个goroutine。
goroutine的新建, 休眠, 恢复, 停止都受到go运行时的管理。
goroutine执行异步操作时会进入休眠状态, 待操作完成后再恢复, 无需占用系统线程。
goroutine新建或恢复时会添加到运行队列, 等待M取出并运行。
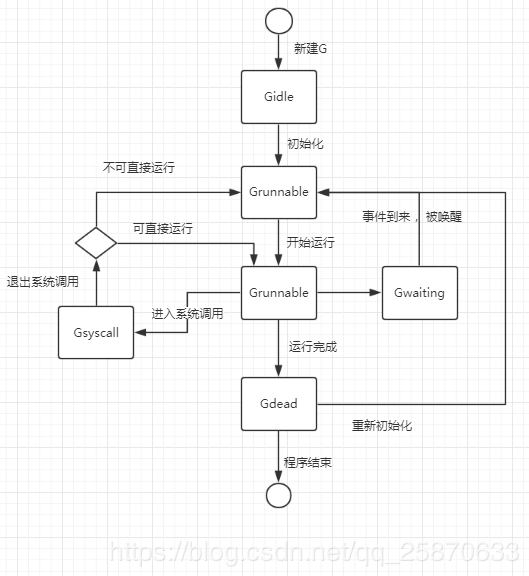 图上有一步是事件到来,那么G在运行过程中,是否等待某个事件以及等待什么样的事件?完全由起封装的go关键字后的函数决定。(如:等待chan中的值、涉及网络I/O、time.Timer、time.Sleep等等事件)
图上有一步是事件到来,那么G在运行过程中,是否等待某个事件以及等待什么样的事件?完全由起封装的go关键字后的函数决定。(如:等待chan中的值、涉及网络I/O、time.Timer、time.Sleep等等事件)
G退出系统调用,及其复杂:运行时系统先会尝试直接运行当前G,仅当无法被运行时才会转成Grunnable并放置入调度器的自由G列表中。
最后,已经是Gdead状态的G是可以被重新初始化并使用的。而对比进入Pdead状态的P等待的命运只有被销毁。处于Gdead的G会被放置到本地P或者调度器的自由G列表中。 goroutine使用的是轻量级线程,即M:N模型,本质是用户线程,其调用是由goroutine调度器实现,并不由内核来调用,用户线程的好处是:轻量,开销小,但问题是并不能避免一个线程阻塞使得整个进程阻塞的问题,但goroutine调度器解决了这个问题。 goroutine对系统线程(内核级线程)进行了封装,暴露了一个轻量级的协程goroutine(用户级线程)供用户使用,而用户级线程到内核级线程的调度由golang的runtime负责,调度逻辑对外透明
总结G-P-M
一句话概括三者关系:
G需要绑定在M上才能运行; M需要绑定P才能运行;
下面我们看一看三者及内核调度实体【KSE】的关系:
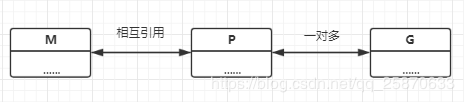
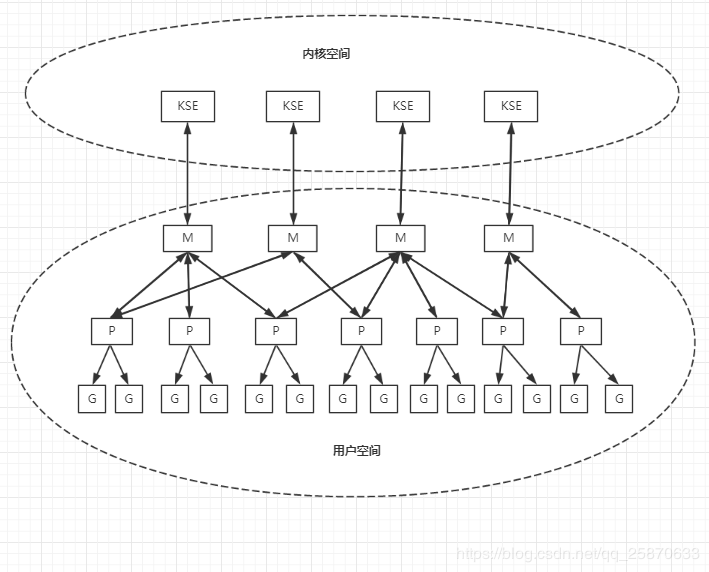 综上所述,一个G的执行需要M和P的支持。一个M在于一个P关联之后就形成一个有效的G运行环境 【内核线程 + 上下文环境】。每个P都含有一个 可运行G的队列【runq】。队列中的G会被一次传递给本地P关联的M并且获得运行时机。
综上所述,一个G的执行需要M和P的支持。一个M在于一个P关联之后就形成一个有效的G运行环境 【内核线程 + 上下文环境】。每个P都含有一个 可运行G的队列【runq】。队列中的G会被一次传递给本地P关联的M并且获得运行时机。
由上图可以看出 M 与 KSE 总是 一对一 的。一个M能且仅能代表一个内核线程。
一个M的生命周期内,它会且仅会与一个KSE产生关联。M与P以及P与G之间的关联是多变的,总是会随着实际调度的过程而改变。其中, M 与 P 总是一对一,P 与 G 总是 一对多, 而 一个 G 最终由 一个 M 来负责运行。
上述我们讲的运行时系统其实就是我们下面要说的调度器。
调度器
调度器代码解析:https://blog.csdn.net/robertkun/article/details/80035648
参考:https://blog.csdn.net/qq_25870633/article/details/83445946 https://blog.csdn.net/weixin_40165163/article/details/90038008
Author sorvik
LastMod 2020-02-20