rust-os.09 paging-introduction
Contents
Paging on x86_64
x86_64体系结构使用4级页表,页大小为4KiB。每个页表独立于级别,有512个固定大小的条目。每个条目的大小为8字节,因此每个表的大小为512*8B=4KiB,因此正好适合一个页面。
级别的页表索引直接从虚拟地址派生:
 我们看到每个表索引由9位组成,这是有意义的,因为每个表有2^9=512个条目。最低的12位是4KiB页中的偏移量(2^12字节=4KiB)。位48到64被丢弃,这意味着x86_64不是真正的64位,因为它只支持48位地址。
即使位48到64被丢弃,它们也不能设置为任意值。相反,此范围内的所有位都必须是位47的副本,以便保持地址唯一,并允许将来扩展,如5级页表。这被称为符号扩展,因为它与two补语中的符号扩展非常相似。当地址没有正确的符号扩展时,CPU抛出一个异常。
值得注意的是,最近的“冰湖”英特尔CPU可选地支持5级页表,将虚拟地址从48位扩展到57位。考虑到在这个阶段为一个特定的CPU优化内核是没有意义的,在本文中我们将只使用标准的4级页表。
我们看到每个表索引由9位组成,这是有意义的,因为每个表有2^9=512个条目。最低的12位是4KiB页中的偏移量(2^12字节=4KiB)。位48到64被丢弃,这意味着x86_64不是真正的64位,因为它只支持48位地址。
即使位48到64被丢弃,它们也不能设置为任意值。相反,此范围内的所有位都必须是位47的副本,以便保持地址唯一,并允许将来扩展,如5级页表。这被称为符号扩展,因为它与two补语中的符号扩展非常相似。当地址没有正确的符号扩展时,CPU抛出一个异常。
值得注意的是,最近的“冰湖”英特尔CPU可选地支持5级页表,将虚拟地址从48位扩展到57位。考虑到在这个阶段为一个特定的CPU优化内核是没有意义的,在本文中我们将只使用标准的4级页表。
一个翻译虚拟地址到物理地址的例子
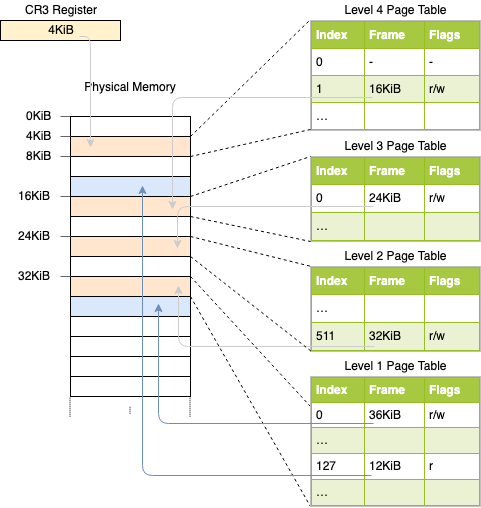 当前活动的4级页表的物理地址(4级页表的根)存储在CR3寄存器中。然后,每个页表条目都指向下一级表的物理框架。然后,级别1表的条目指向映射的帧。注意,页表中的所有地址都是物理的而不是虚拟的,因为否则CPU也需要转换这些地址(这可能会导致无休止的递归)。
上面的页表层次结构映射了两页(蓝色)。从页表索引可以推断这两个页的虚拟地址是0x803FE7F000和0x803FE00000。让我们看看当程序试图从地址0x803FE7F5CE读取时会发生什么。首先,我们将地址转换为二进制,并确定地址的页表索引和页偏移量:
当前活动的4级页表的物理地址(4级页表的根)存储在CR3寄存器中。然后,每个页表条目都指向下一级表的物理框架。然后,级别1表的条目指向映射的帧。注意,页表中的所有地址都是物理的而不是虚拟的,因为否则CPU也需要转换这些地址(这可能会导致无休止的递归)。
上面的页表层次结构映射了两页(蓝色)。从页表索引可以推断这两个页的虚拟地址是0x803FE7F000和0x803FE00000。让我们看看当程序试图从地址0x803FE7F5CE读取时会发生什么。首先,我们将地址转换为二进制,并确定地址的页表索引和页偏移量:
 使用这些索引,我们现在可以遍历页表层次结构来确定地址的映射帧:
使用这些索引,我们现在可以遍历页表层次结构来确定地址的映射帧:
- 我们首先从CR3寄存器中读取4级表的地址。
- 4级索引是1,所以我们查看该表的索引为1的条目,它告诉我们3级表存储在地址16KiB。
- 我们从该地址加载3级表,并查看索引为0的条目,该条目将我们指向24KiB处的2级表。
- 二级索引是511,因此我们查看该页的最后一个条目,找出一级表的地址。
- 通过一级表的索引127条目,我们最终发现该页映射到第12KiB帧,或十六进制的0x3000帧。
- 最后一步是将页偏移量添加到帧地址以获得物理地址0x3000+0x5ce=0x35ce。
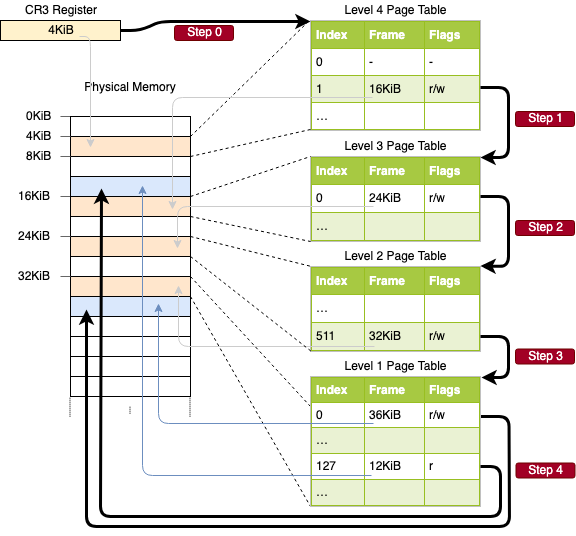 级别1表中页的权限是r,这意味着只读。硬件强制执行这些权限,如果我们试图写入该页,则会引发异常。较高级别页中的权限限制较低级别的可能权限,因此,如果将级别3项设置为只读,则使用此项的页都不能写入,即使较低级别指定了读/写权限。
需要注意的是,尽管这个示例只使用了每个表的一个实例,但每个地址空间中通常都有每个级别的多个实例。最多有:
级别1表中页的权限是r,这意味着只读。硬件强制执行这些权限,如果我们试图写入该页,则会引发异常。较高级别页中的权限限制较低级别的可能权限,因此,如果将级别3项设置为只读,则使用此项的页都不能写入,即使较低级别指定了读/写权限。
需要注意的是,尽管这个示例只使用了每个表的一个实例,但每个地址空间中通常都有每个级别的多个实例。最多有:
- 一张四级表,
- 512个3级表(因为4级表有512个条目),
- 512*512级别2表(因为512级别3表中的每个表都有512个条目),以及
- 512512512级别1表(每个级别2表有512个条目)。
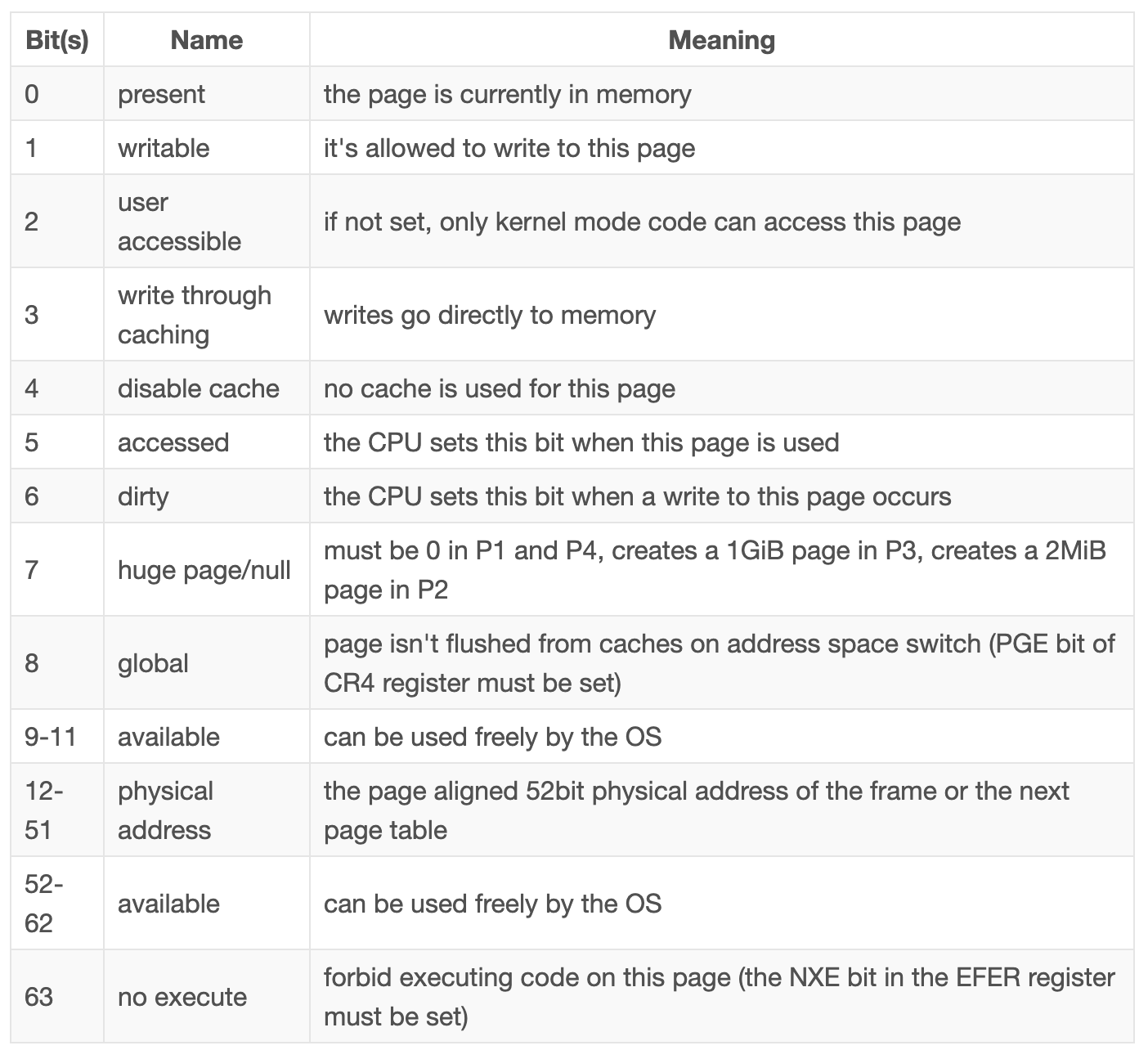 让我们仔细看看可用的标志:
让我们仔细看看可用的标志:
- present flag 将映射页与未映射页区分开来。它可用于在主内存满时将页临时交换到磁盘。当随后访问该页时,会发生一个称为页错误(page fault)的特殊异常,操作系统可以通过从磁盘重新加载丢失的页,然后继续执行程序来对此做出反应。
- writable 和 no execute flags分别控制页面内容是可写的还是包含可执行指令。
- 当对页面进行读写操作时,CPU会自动设置访问标志和脏标志(accessed and dirty flags)。操作系统可以利用此信息,例如,决定要交换哪些页面,或者自上次保存到磁盘后是否修改了页面内容。
- write through caching 和 disable cache flags允许分别控制每个页面的缓存。
- user accessible flag使页面对用户空间代码可用,否则只有在CPU处于内核模式时才可访问。此功能可用于在用户空间程序运行时保持内核映射,从而使系统调用更快。但是,幽灵漏洞仍然允许用户空间程序读取这些页面。
- global flag向硬件发出信号,表明页在所有地址空间中都可用,因此不需要从地址空间开关上的转换缓存中删除(请参阅下面关于TLB的部分)。此标志通常与清除的用户可访问标志一起使用,以将内核代码映射到所有地址空间。
- huge page flag允许通过让级别2或级别3页面表的条目直接指向映射的框架来创建更大的页面。设置此位后,页面大小将增加512倍,级别2条目的页面大小为2MiB=5124KiB,级别3条目的页面大小甚至为1GiB=5122MiB。使用较大页面的优点是,需要更少的翻译缓存行和更少的页表。
TLB(The Translation Lookaside Buffer)
翻译查找缓冲区 一个4级的页表使得虚拟地址的转换非常昂贵,因为每个转换需要4次内存访问。为了提高性能,x86_64体系结构将最后几个翻译缓存在所谓的翻译查找缓冲区(translation lookaside buffer,TLB)中。这允许在翻译仍处于缓存状态时跳过翻译。 与其他CPU缓存不同,TLB不是完全透明的,并且在页表内容更改时不会更新或删除翻译。这意味着内核必须在修改页表时手动更新TLB。为此,有一个名为invlpg(“invalidate page”)的特殊CPU指令,它从TLB中删除指定页的转换,以便在下次访问时从页表中再次加载该页。TLB也可以通过重新加载CR3寄存器来完全刷新,该寄存器模拟地址空间开关。 记住在每次修改页表时刷新TLB是很重要的,因为否则CPU可能会继续使用旧的转换,这可能会导致非常难调试的不确定错误。
Author sorvik
LastMod 2020-03-07