Introduction to Parallel Computing
Contents
overview
这是一个超算实验室的一篇关于并行计算的文章
Supercomputing / High Performance Computing (HPC) Using the world’s fastest and largest computers to solve large problems.
The programmer is responsible for many of the details associated with data communication between processors. 程序员负责与处理器之间的数据通信相关的许多细节
Flynn分类法
有多种方法可以对并行计算机进行分类。此处提供示例。
自1966年以来一直使用的一种更广泛使用的分类称为Flynn’s Taxonomy。
Flynn的分类法根据如何按照指令流和数据流的两个独立维度对多处理器计算机体系结构进行分类来区分它们。这些维度中的每一个只能具有以下两种可能状态之一:单个或多个。
下面的矩阵根据Flynn定义了4种可能的分类:
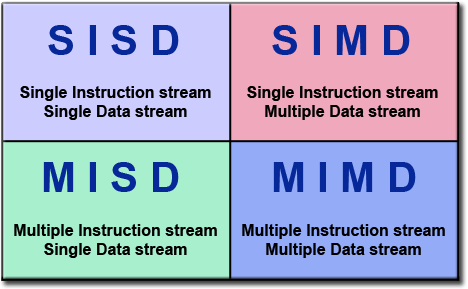 Single Instruction: Only one instruction stream is being acted on by the CPU during any one clock cycle
Single Data: Only one data stream is being used as input during any one clock cycle
Single Instruction: Only one instruction stream is being acted on by the CPU during any one clock cycle
Single Data: Only one data stream is being used as input during any one clock cycle
Limits and Costs of Parallel Programming
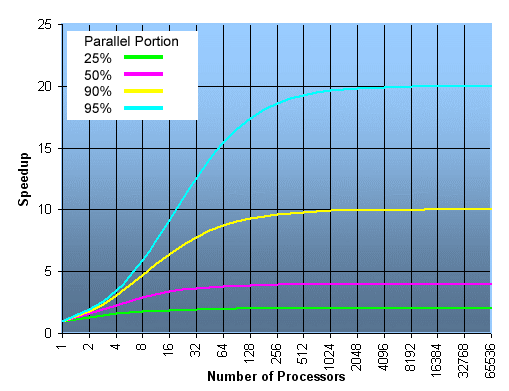
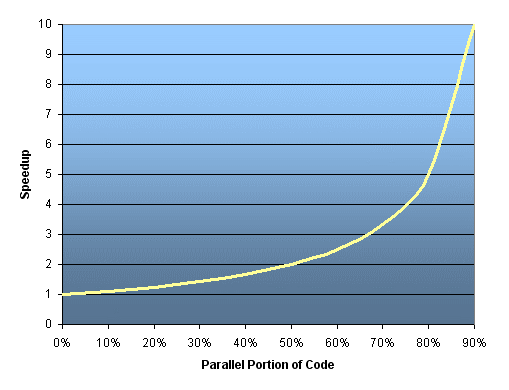
Amdahl’s Law states that potential program speedup is defined by the fraction of code (P) that can be parallelized:
1
speedup = --------
1 - P
If none of the code can be parallelized, P = 0 and the speedup = 1 (no speedup). If all of the code is parallelized, P = 1 and the speedup is infinite (in theory). If 50% of the code can be parallelized, maximum speedup = 2, meaning the code will run twice as fast. Introducing the number of processors performing the parallel fraction of work, the relationship can be modeled by:
1
speedup = ------------
P + S
---
N
where P = parallel fraction, N = number of processors and S = serial fraction.
复杂性 Complexity:
In general, parallel applications are much more complex than corresponding serial applications, perhaps an order of magnitude. Not only do you have multiple instruction streams executing at the same time, but you also have data flowing between them. The costs of complexity are measured in programmer time in virtually every aspect of the software development cycle: Design Coding Debugging Tuning Maintenance Adhering to “good” software development practices is essential when working with parallel applications - especially if somebody besides you will have to work with the software.
所需资源 Resource Requirements:
并行编程的主要目的是减少执行挂钟时间,但是要实现这一点,需要更多的CPU时间。例如,在8个处理器上运行1小时的并行代码实际上会占用8小时的CPU时间。
由于需要复制数据以及与并行支持库和子系统相关的开销,因此并行代码比串行代码所需的内存量可能更大。
对于短期运行的并行程序,与类似的串行实现相比,实际上可能会降低性能。与设置并行环境,任务创建,通信和任务终止相关的间接费用可能占短期总执行时间的很大一部分
可扩展性,可伸缩性 scalability
硬件因素在可伸缩性中起着重要作用。例子:
SMP机器上的Memory-cpu总线带宽
通讯网络带宽
任何给定机器或一组机器上可用的内存量
处理器时钟速度
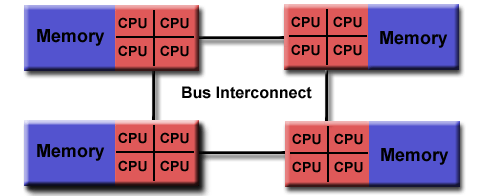
Parallel Computer Memory Architectures
并行计算机内存架构
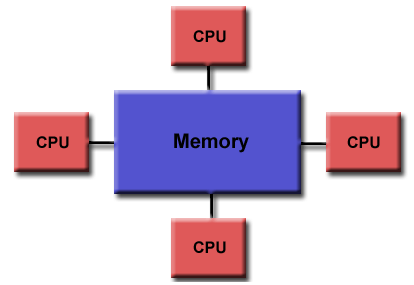
共享内存
一般特征 General Characteristics:
Shared memory parallel computers vary widely, but generally have in common the ability for all processors to access all memory as global address space. 共享内存并行计算机差别很大/很广泛,但一般都有一个共同的能力,即所有处理器都能以全局地址空间的形式访问所有内存。
多个处理器可以独立运行,但是共享相同的内存资源。
一个处理器影响的内存位置更改对所有其他处理器可见。
从历史上看,基于内存访问时间,共享内存计算机已分为UMA和NUMA
Author sorvik
LastMod 2020-11-29