流水线
Contents
五级流水线
wiki
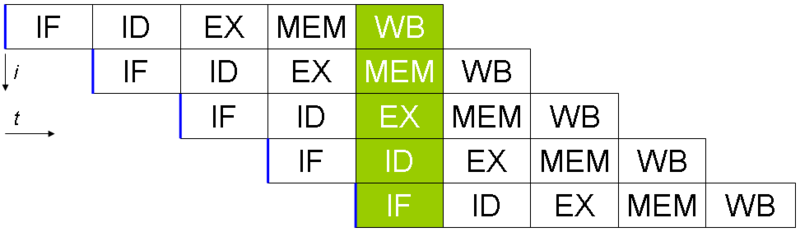 Basic five-stage pipeline in a RISC machine (IF = Instruction Fetch, ID = Instruction Decode, EX = Execute, MEM = Memory access, WB = Register write back). The vertical axis is successive instructions; the horizontal axis is time. So in the green column, the earliest instruction is in WB stage, and the latest instruction is undergoing instruction fetch.
Basic five-stage pipeline in a RISC machine (IF = Instruction Fetch, ID = Instruction Decode, EX = Execute, MEM = Memory access, WB = Register write back). The vertical axis is successive instructions; the horizontal axis is time. So in the green column, the earliest instruction is in WB stage, and the latest instruction is undergoing instruction fetch.
Instruction fetch
The instructions reside in memory that takes one cycle to read. This memory can be dedicated SRAM, or an Instruction Cache. 指令驻留在需要一个周期才能读取的内存中。这个内存可以是专用SRAM或指令缓存
Instruction decode
https://en.wikipedia.org/wiki/Classic_RISC_pipeline#Instruction_decode
Execute
ALU作用
The ALU is responsible for performing boolean operations (and, or, not, nand, nor, xor, xnor) and also for performing integer addition and subtraction. Besides the result, the ALU typically provides status bits such as whether or not the result was 0, or if an overflow occurred. ALU负责执行布尔运算(and, or, not, nand, nor, xor, xnor),也负责执行整数加和减。除了结果之外,ALU通常还提供状态位,比如结果是否为0,或者是否发生了溢出。
Memory access
Writeback
写回寄存器(register file) 有可能写回的时候目标寄存器正在被读(比如五级流水线中的第二步ID),这时候就是一种Hazards
SRAM
Static random-access memory wiki SRAM是易失性存储器;断开电源后,数据将丢失。 静态一词将SRAM与DRAM(动态随机存取存储器)区分开来,后者必须定期刷新。 SRAM比DRAM更快,更昂贵。它通常用于CPU缓存,而DRAM用于计算机的主内存。
Pipeline bubble
wiki A pipelined processor may deal with hazards by stalling and creating a bubble in the pipeline, resulting in one or more cycles in which nothing useful happens. 流水线处理器处理hazards的方法可能是在流水线中阻塞(stall)和产生气泡(bubble),导致一个或多个没有任何有用的事情发生的周期。
Pipeline stall
wiki The processor may stall due to a cache miss, branch misprediction, or data dependency.
流水线的深度和宽度
增加深度比如20级流水线,就是超级流水线的路子
拓宽宽度就是多加几套流水线,就是多发射,超标量,还有inter的超线程等等的路子
多发射 Mulitple issue
多发射处理器基本上有两种变体-超标量处理器和VLIW(超长指令字)处理器
有两种类型的超标量处理器,每个时钟发出不同数量的指令。他们是
- 使用顺序执行的静态调度超标量
- 使用乱序执行的动态调度的超标量
超标量处理器可以实时确定要发出多少指令。如果指令以程序顺序发布到后端,则我们有顺序处理器。有序处理器是静态调度的,即调度是在编译时完成的。静态调度的超标量必须检查发布数据包中的指令与流水线中已存在的任何指令之间的依赖关系。它们需要大量的编译器帮助才能获得良好的性能,因为编译器完成了查找和调度并行执行指令的大部分工作。 相反,动态调度的超标量需要较少的编译器帮助,但需要大量硬件。如果指令可以以任何顺序发布到后端,则我们有乱序(OOO)处理器。 OOO处理器由硬件动态调度。
VLIW
无论是乱序执行、还是超标量技术、在实际的硬件层面、都需要解决依赖冲突(冒险)问题、所以、实施会比较复杂 CPU需要在指令执行之前、判断指令是否有依赖关系、若有, 则不能分发到不同的执行阶段、 所以: 超标量CPU发射、又被称为动态多发射处理器 对于 依赖关系的检测、会使得CPU电路变的更加复杂
于是: 科学家有一个大胆的想法: 将分析和解决依赖关系的事情、放到软件里
超长指令设计: VLIW(Very Long Insturction Word)、想通过编译器来优化CPI
编译器在汇编完成之后、也可以知道前后数据的依赖、可以让编译器把没有依赖关系的代码位置进行交换、然后把多条连续的指令打成一个指令包、安腾的CPU就是把3条指令打成一个指令包, 如下图所示:
CPU在运行的时候、就不再是取一条指令、而是取一个指令包、然后译码解析整个指令包、解析出3条指令并行运行
2.流水线停顿、也是编译器来做了、除了停下整个处理器流水线、CPU不能在某个周期停顿一下、等待前边依赖的操作完成、编译器需要在适当的位置插入NOP操作、直接在编译出来的机器码里、把流水线停顿设计完成
Author sorvik
LastMod 2020-12-27